HTTP/浏览器
HTTP/浏览器篇(第一个版本预计总结常见问题15个左右)
从地址栏输入URL到呈现页面
简洁来说过程如下:
1.浏览器向
DNS服务器请求解析该 URL 中的域名所对应的IP地址;2.建立
TCP连接(三次握手);3.浏览器发出读取文件(
URL中域名后面部分对应的文件)的HTTP请求,该请求报文作为TCP三次握手的第三个报文的数据发送给服务器;4.服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5.浏览器将该
html文本并显示内容;6.释放
TCP连接(四次挥手);
浏览器解析渲染过程,见HTML&CSS
DNS--解析顺序
解析顺序:按照浏览器缓存,系统缓存,路由器缓存,ISP(运营商)DNS缓存,根域名服务器,顶级域名服务器,主域名服务器逐步读取,直到拿到IP地址
DNS递归查询和迭代查询:从客户端到本地DNS服务器是属于递归查询,而DNS服务器之间就是的交互查询就是迭代查询
建立和释放TCP连接的过程,能画一下嘛
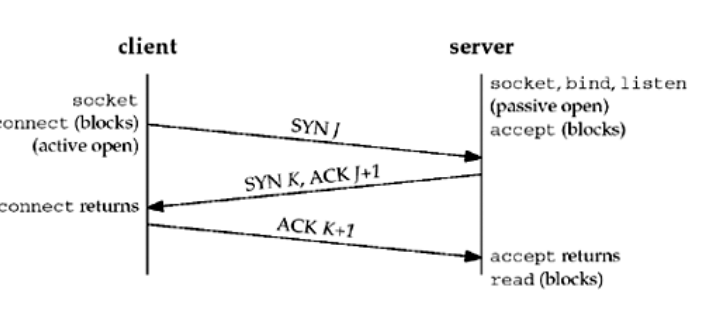
三次握手:(SYN (同步序列编号)ACK(确认字符))
第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等 待Server确认。
第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态
第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
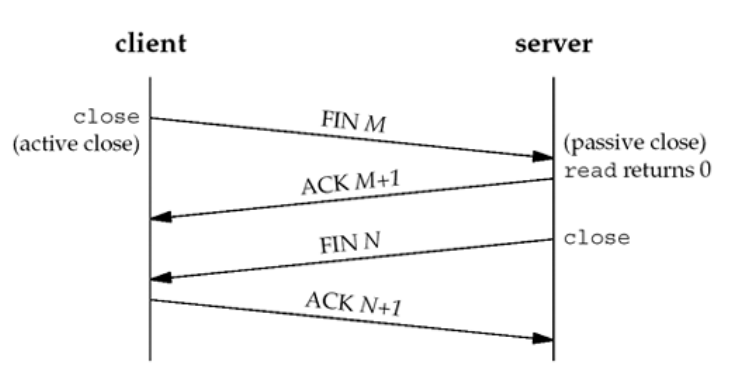
四次挥手:
第一次挥手:Client发送一个FIN=M(释放一个连接),用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
第二次挥手:Server收到FIN后,发送一个ack=M+1给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
第三次挥手:Server发送一个FIN = N,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号ack=N+1,Server进入CLOSED状态,完成四次挥手
追问:释放连接的过程是四次挥手,相比建立连接过程为什么要多一次?
因为服务端收到SYN建连报文后,可以把ACK报文和SYN报文放在一起发送。但是当关闭连接的时候,当对方收到FIN报文通知时,仅仅表示对方已经无数据发送给你了,但未必你已经发送完全部数据,这时就不能马上关闭socket,所以释放连接过程SYN包和ACK包要分开发送。
HTTP方法知道哪些,GET和POST区别有哪些
HTTP1.0定义了三种请求方法,GET,POST和HEAD方法 HTTP1.1新增六种请求方法:OPTIONS,PUT,PATCH,DELETE,TRACH和CONNECT
GET和POST区别主要从三方面讲即可:表现形式,传输数据大小,安全性
首先表现形式上:GET请求的数据会附加在URL后面,以?分割多参数用&连接,由于URL采用ASCII编码,所以非ASCII字符会先编码在传输,可缓存;POST请求会把请求的数据放在请求体中,不可缓存
传输数据大小:对于GET请求,HTTP规范没有对URL长度进行限制,但是不同浏览器对URL长度加以限制,所以GET请求时,传输数据会受到URL长度的限制;POST不是URL传值,理论上无限制,但各个服务器一般会对POST传输数据大小进行限制
安全性:相比URL传值,POST利用请求体传值安全性更高
PS:还有一种GET产生一个数据包,POST产生两个数据包的说法可答可不答,并不是所有浏览器如此,铺展开解释来说就是:对GET请求,浏览器会把请求头和data一起发送,服务器响应200(返回数据),对于POST请求,浏览器会先发送header,服务器响应100后继续,浏览器再发送data,服务器响应200
HTTP的缓存过程(强缓存和协商缓存)
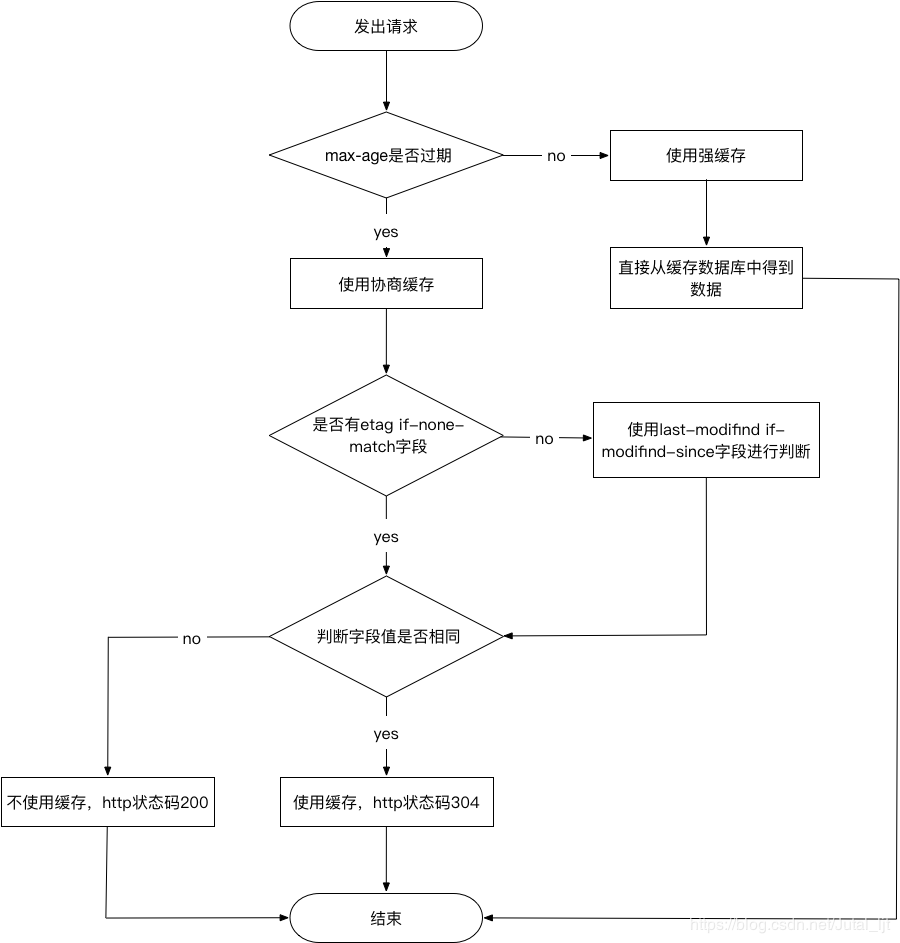
通常过程如下:
判断是否过期(服务器会通知浏览器一个缓存时间,相关头部信息在Cache-Control和Expires中),如果时间未过期,则直接从缓存中取,即强缓存;
Cache-Control
其中
max-age = <seconds>设置缓存存储的最大周期,超过这个时间缓存将会被认为过期,与Expires相反,时间是相对于请求的时间public 表示响应可以被任何对象缓存,即使是通常不可缓存的内容
private 表示缓存只能被单个用户缓存,不能作为共享缓存(即代理服务器不可缓存它)
no-cache 告诉浏览器、缓存服务器,不管本地副本是否过期,使用副本前一定要到源服务器进行副本有效校验
no-store 缓存不应该存储有关客户端请求或服务器响应的任何内容
Expires
expires 字段规定了缓存的资源的过期时间,该字段时间格式使用GMT时间标准时间格式, js通过
new Date().toUTCString()得到,由于时间期限是由服务器生成,存在着服务端和客户端的时间误差,相比cache-control优先级较低
注:cache-control和expires谁的优先级更高也是校招面试中常问的问题(腾讯一面被问过)
那么如果判断缓存时间已经过期,将会采用协商缓存策略
Last-Modified响应头和If-Modified-Since请求头
Last-Modified 表示资源最后的修改时间,在浏览器第一次发送HTTP请求时,服务器会返回该响应头
那么浏览器在下次发起HTTP请求时,会带上If-Modified-Since请求头,其值就是第一次发送HTTP请求时,服务器设置在Last-Modified响应头中的值
两种情况:如果资源最后修改时间大于If-Modified-Since,说明资源有被改动过,则响应完整的资源内容,返回状态码200;如果小于或者等于,说明资源未被修改,则响应状态码304,告知浏览器可以继续使用所保存的缓存
Etag响应头和If-None-Match请求头
Etag值为当前资源在服务器的唯一标识
类比上面Last-Modified响应头和If-Modified-Since请求头,请求头中If-None-Match将会和资源的唯一标标识进行对比,如果不同,则说明资源被修改过,响应200;如果相同,则说明资源未改动,响应304
对HTTP报文结构的了解
HTTP报文结构由报文首部,空行,报文主体三部分组成
报文首部
空行
报文主体
而HTTP报文首部则是由首部字段名和字段值键值对形式构成,如Content-Type:text/html
HTTP首部字段通常分为4种类型:通用首部,请求首部,响应首部,实体首部
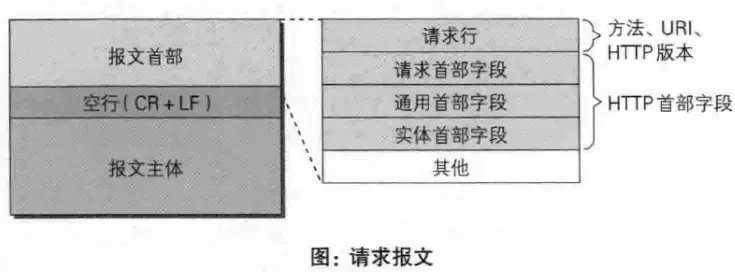
HTTP请求报文,一个HTTP请求报文由请求行(request line)、请求头部(request header)、空行和请求数据4个部分构成。请求行数据格式由三个部分组成:请求方法、URI、HTTP协议版本,他们之间用空格分隔
HTTP响应报文,一个HTTP响应报文由状态行(HTTP版本、状态码)、响应头部、空行和响应体4个部分构成。状态行主要给出响应HTTP协议的版本号、响应返回状态码、响应描述,同样是单行显示
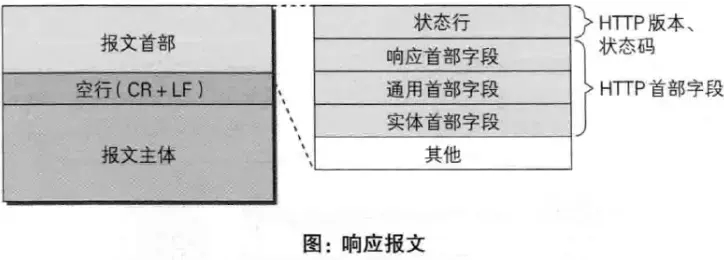
HTTP的状态码,301和302的区别
状态码告知从服务器返回请求的状态,一般由以1~5开头的三位整数组成,
1xx:请求正在处理
2xx:成功
3xx:重定向
301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
302 found,临时性重定向,表示资源临时被分配了新的 URL
303 see other,表示资源存在着另⼀个 URL,应使⽤ GET ⽅法定向获取资源
304 not modified,表示服务器允许访问资源,但因发生请求未满足条件的情况
307 temporary redirect,临时重定向,和302含义相同
4xx:客户端错误
400 bad request,请求报文存在语法错误
401 unauthorized,表示发送的请求需要有通过HTTP认证的认证信息
403 forbidden,表示对请求资源的访问被服务器拒绝
404 not found,表示服务器上没找到请求的资源
408 Request timeout,客户端请求超市
409 confict,请求的资源可能引起冲突
5xx:服务器错误
500 internal server error,表示服务器端在执行请求时发生了错误
501 Not Implemented,请求超出服务器能力范围
503 service unavailable,表示服务器暂时处于超负载或正在停机维护,无法处理
505 http version not supported,服务器不支持,或者拒绝支持在请求中的使用的HTTP版本
同样是重定向,302是HTTP1.0的状态码,在HTTP1.1版本的时候为了细化302又分出来了303和307,303则明确表示客户端应采用get方法获取资源,他会把post请求变成get请求进行重定向;307则会遵照浏览器标准,不会改变post
HTTP建立持久连接的意义
HTTP持久连接也称作HTTP keep-alive,使用同一个TCP连接发送和接收多个HTTP请求,是HTTP1.1的新特性,HTTP1.1默认所有连接都是持久连接。在HTTP1.0,使用非持久连接,每个TCP连接只用于传输一个请求和响应,没有官方的keepalive操作,如果浏览器支持通常在请求和响应头中加上Connection: Keep-Alive
那么由于同时打开的TCP连接减少,可以减少内存和CPU的占用;其次之后也无需再次握手,也减少了后续请求的延迟
HTTP1.1相比1.0的区别有哪些
目前通用标准是HTTP1.1,在1.0的基础上升级加了部分功能,主要从连接方式,缓存,带宽优化(断点传输),host头域,错误提示等方面做了改进和优化
连接方式:HTTP1.0使用短连接(非持久连接);HTTP1.1默认采用带流水线的长连接(持久连接),PS:在持久连接的基础上可选的是管道化的连接
缓存:HTTP1.1新增例如ETag,If-None-Match,Cache-Control等更多的缓存控制策略
带宽优化:HTTP1.0在断连后不得不下载完整的包,存在一些带宽浪费的现象;HTTP1.1则支持断点续传的功能,在请求消息中加入range 头域,允许请求资源的某个部分,在响应消息中Content-Range头域中声明了返回这部分对象的偏移值和长度
host头域:在HTTP1.0中每台服务器都绑定一个唯一的ip地址,所有传递消息中的URL并没有传递主机名;HTTP1.1请求和响应消息都应支持host头域,且请求消息中没有host头域名会抛出一个错误(400 Bad Request)
错误提示:HTTP1.1新增24个状态响应码,比如409(请求的资源与资源当前状态冲突),410(服务器上某个资源被永久性删除);相比HTTP1.0只定义了16个状态响应码
HTTP2相比HTTP1的优势和特点
HTTP2相比HTTP1.x有4大特点,二进制分帧,头部压缩,服务端推送和多路复用
①二进制分帧:HTTP2使用二进制格式传输数据,而HTTP1.x使用文本格式,二进制协议解析更高效
②头部压缩:HTTP1.x每次请求和发送都携带不常改变的,冗杂的头部数据,给网络带来额外负担;而HTTP2在客户端和服务器使用"部首表"来追踪和存储之前发送的键值对,对于相同的数据,不再每次通过每次请求和响应发送
可以简单理解为只发送差异数据,而不是发送全部头部,从而减少头部信息量)
③服务端推送:服务端可以在发送页面HTML时主动推送其他资源,而不用等到浏览器解析到相应位置时,发起请求再响应
④多路复用:在HTTP1.x中如果想并发多个请求,需要多个TCP连接,并且浏览器为了控制资源,一般对单个域名有6-8个TCP连接数量的限制;而在HTTP2中
同个域名所有通信都在单个连接下进行
单个连接可以承载任意数量的双向数据流
数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送
HTTPS相比HTTP的区别,讲一下HTTPS的实现过程
https相比之下是安全版的http,其实就是HTTP over TSL,因为http都是使用明文传输的,对于敏感信息的传输就很不安全,https正是为了解决http存在的安全隐患而出现的
https的实现也是一个较复杂的过程,将对称加密的密钥使⽤⾮对称加密的公钥进⾏加密,在保证了通信效率的同时防止窃听,同时结合CA证书以及数字签名来最大程度保证安全性:
对称加密:通信双方都使用用一个密钥进行加密解密,比如特工接头的暗号,就属于对称加密;这种方式虽然简单性能好,但是无法解决首次把密钥发给对方的问题,容易被黑客拦截密钥
非对称加密:由私钥+公钥组成的密钥对
即用私钥加密的数据,只要公钥才能解密;用公钥加密的数据,只有私钥才能解密
通信双方都有自己的一套密钥对,通信前将自己的公钥发给对方
然后拿着这个公钥来加密数据响应给对方,等对方收到之后,再用自己的私钥进行解密
非对称加密虽然安全性更高,但是带来的问题就是速度较慢,影响性能
结合两种方式,将对称加密的密钥使用非对称加密的公钥进行加密,然后再发送出去,然后接收方使用自己的私钥进行解密得到对称加密的密钥
但是又带来一个问题,即中间人问题:
如果此时在客户端和服务端之间存在一个中间人,这个中间人只需要把原本双方通信互发的公钥,换成自己的公钥,这样中间人就可以轻松解密通信双方所发送的数据
这时候就需要一个安全的第三方的颁布证书,来证明身份,防止中间攻击:所以就有了CA证书,仔细观察浏览器地址栏,会有一个"小锁"的标志,点开里面有证明身份的CA证书信息
但是仍然存在的一个问题是,如果中间人篡改了CA证书,那么这个证书不就无效了?所以就添加了新的保护方案:数字签名
数字签名就是用证书自带的HASH算法对证书内容进行一个HASH得到一个摘要,再用CA的私钥进行加密,最终组成数字签名
当别人把他的证书发过来时,用同样的HASH算法得到信息摘要,然后再用CA的公钥对数字签名进行解密,得到CA创建的消息摘要,两者一对比就知道中间有没有被篡改了
通过这样的方式,https最大化保证了通信的安全性
对Websocket的了解,应用场景,对比HTTP
Websocket和HTTP都是基于TCP协议两个不同的协议
首先Websocket是一种在单个TCP连接上进行全双工通信的协议,允许服务端主动向客户端推送数据(只需要一次握手,两者之间创建持久化连接,可进行双向数据传输);而HTTP则需要定时轮询向服务器请求,然后服务器再向客户端发送数据
其次,HTTP是一个无状态协议,缺少状态意味着后续处理需要先前数据必须重传;而Websocket需要先创建连接,这就使得其成为一种有状态的协议,之后通信时可以省略部分状态信息
应用场景:如果应用是多个用户相互交流,或者展示服务端经常变动的数据都可以考虑websocket;所以体育实况,多媒体聊天等这些都是Websocket不错的应用场景
TCP和UDP区别有哪些
TCP
UDP
是否连接
面向连接
面向非连接
传输可靠性
可靠
不可靠
应用场景
少量数据
传输大量数据
速度
慢
快
TCP是面向连接的;UDP则是无连接的,即发送数据之前不需要建立连接
TCP提供的可靠的服务,即TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;而UDP尽最大努力,不保证可靠交付
TCP面向字节流,TCP把数据看成一连串无结构的字节流;UDP是面向报文的
每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
TCP首部开销较大,20字节;UDP只有8字节
TCP的逻辑通信信道是全双工的可靠信道;而UDP则是不可靠信道
前端性能优化的方案有哪些
前端性能优化七大常用的优化手段:减少请求数量,减小资源大小,优化网络连接,优化资源加载,减少回流重绘,使用更好性能的API和构建优化
减少请求数量
文件合并,并按需分配(公共库合并,其他页面组件按需分配)
图片处理:使用雪碧图,将图片转码base64内嵌到HTML中,使用字体图片代替图片
减少重定向:尽量避免使用重定向,当页面发生了重定向,就会延迟整个HTML文档的传输
使用缓存:即利用浏览器的强缓存和协商缓存
不使用CSS @import:CSS的@import会造成额外的请求
避免使用空的src和href:a标签设置空的href,会重定向到当前的页面地址,form设置空的method,会提交表单到当前的页面地址
减小资源大小
压缩:静态资源删除无效冗余代码并压缩
webp:更小体积
开启gzip:HTTP协议上的GZIP编码是一种用来改进WEB应用程序性能的技术
优化网络连接
使用CDN
使用DNS预解析:DNS Prefetch,即DNS预解析就是根据浏览器定义的规则,提前解析之后可能会用到的域名,使解析结果缓存到
系统缓存中,缩短DNS解析时间,来提高网站的访问速度
并行连接:由于在HTTP1.1协议下,chrome每个域名最大并发数是6个。使用多个域名,可以增加并发数
管道化连接:在HTTP2协议中,可以开启管道化连接,即单条连接的多路复用
优化资源加载
减少重绘回流
使用性能更好的API
构建优化:如webpack优化
参考:前端性能优化的七大手段
Last updated
Was this helpful?